EverMinerSimple Demo Example
A more complex example of (simplified) data mining automation is provided.The EverMiner is a research goal of full-scale knowledge-data-discovery automation. It is based on general phases of KDD and on research in observational logic operations (namely of deduction and inferring new knowledge). It is supposed to formulate reasonable analytical tasks to look-up interesting and not yet known patterns in analyzed data.
One import prerequisite for automation is a high-level language to control data preprocessing, analytical tasks settings and to provide means for digesting mined results and for inferring new domain knowledge. Thus, the LISp-Miner Control Language main goal is to provide such a tool.
The EverMinerSimple demo is a really simplified version of the EverMiner, which only purpose is to proof that the LMCL is really able to automate the KDD process.
The EverMinerSimple implements only one iteration of the main phases with no new domain knowledge from results inferred yet. But it already incorporates the inner cycle of fine-tuning tasks parameters to obtain an acceptable number of patterns in results (this number is an input parameter -- see below).
There is a conceptual diagram of EverMinerSimple steps in the picture 1.
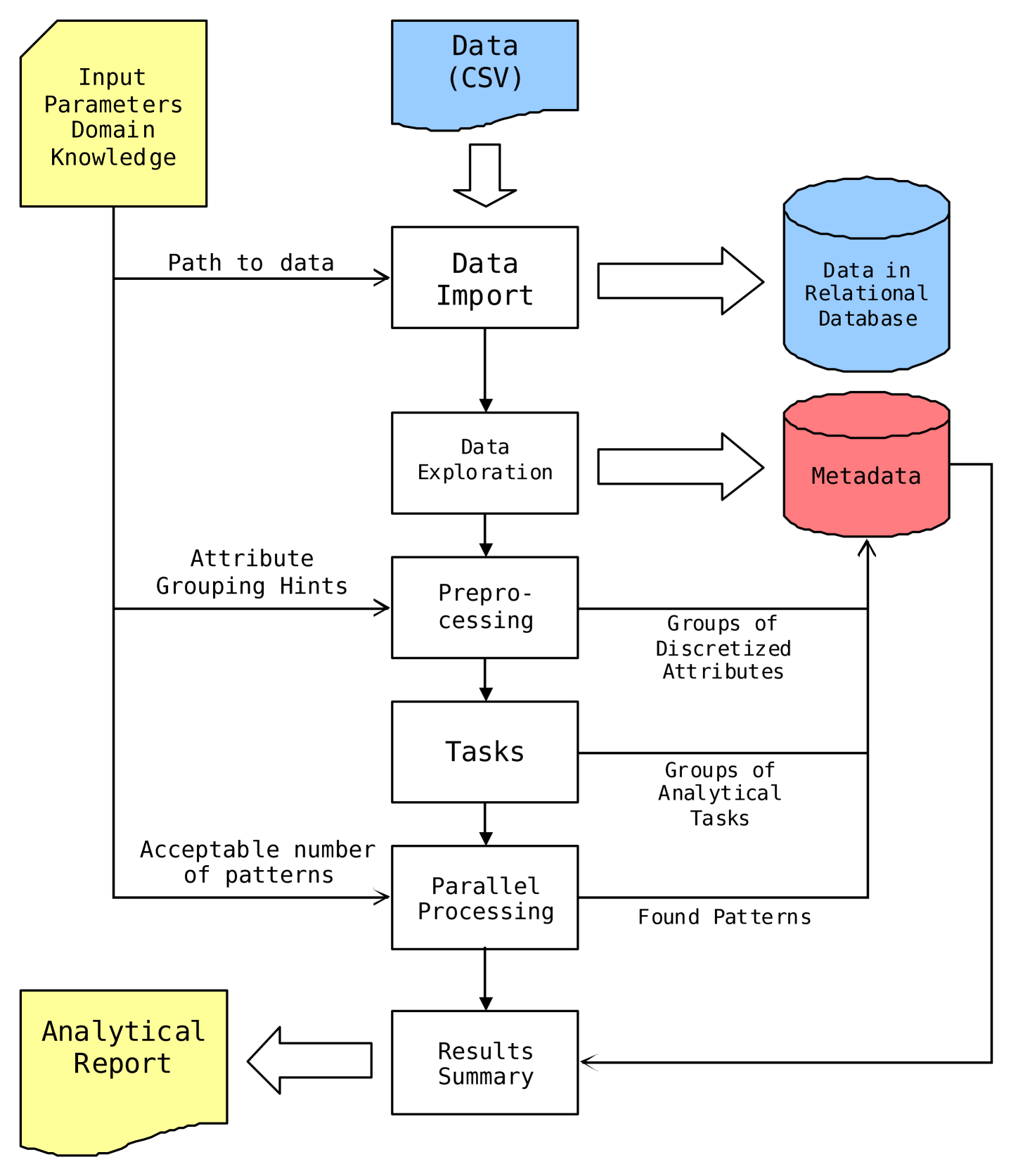
Pic. 1 -- EverMinerSimple conceptual diagram
<LM root>
\Exec\Demo\EverMinerSimple\_EverMinerSimple.lua
It consists of input parameters and a sequence of calls to high level functions corresponding to steps in the conceptual diagram above.
Input parameters
Few user-defined parameters provide all the necessary input to the whole process.The first group of parameters defines the text file with analyzed data to import, destinations to store the created database with analyzed data and the database with meta-data. Finally, it defines the ODBC DataSourceName to identify this data + meta-data pair within the operating system.
The second group of parameters provides a bit of domain knowledge � groups of attributes the analyzed data columns should be grouped into. This information is important for analytical tasks construction, where all the possible combinations of groups of attributes in antecedents and succedents of patterns to be mined are created.
The most interesting input parameters are the minimal and maximal number of patterns to mine, regardless of combination of groups this particular task is concerning. There are several ways how to reduce (or enlarge) task search space to influence the number of found patterns -- see parallel processing below. (A check for maximal number of iteration is implemented to avoid a never-ending cycle.) Another parameter controls platform on which tasks are solved -- either locally on multiple processor cores or remotely on a computer grid. An important feature is that no task settings are changed after it was processed. Every time a change is necessary to task settings, its exact clone is created first and the desired change is made to this cloned task settings instead. Therefore, a complete history of task settings evolution, together with a number and an exact form of found patterns is preserved in the meta-data database. It could be used later for investigations of steps and decisions taken during automated data mining process � either for debug purposes or to help with a proper interpretation of found patterns.
The last input parameter specifies the path and name of file for the analytical report to be written into.
Data import
This phase is executed by calling the
ems.metabase.createDataAndMetabase() from the main file and is
implemented in the<LM root>\Exec\Demo\EverMinerSimple\EMSMetabase.lua file.
It imports data using the lm.data.importTXT(...)
function. Then it creates a fresh metabase
and associates it with previously created database with analyzed data. Finally
it updates meta-information about tables and theirs columns by calling the lm.metabase.updateMetadata()
function.
Data Exploration
This phase is executed by calling the ems.explore.initTables()
from the main file and is implemented in the
<LM root>\Exec\Demo\EverMinerSimple\EMSExplore.lua
file.
It iterates through all the tables in analyzed data database, adds derived columns (eg. DayOfWeek) for Date/Time columns and computes basic statistical informations for each column (min, max, avg...). It also marks the primary key column. Finally, it enables caching to speed up multiple analytical tasks computations on this table.
Data Preprocessing
This phase is executed by calling theems.prepro.createPreprocessing()
from the main file and is implemented in the
<LM root>\Exec\Demo\EverMinerSimple\EMSPrepro.lua
file.
First, it creates groups of attributes following the domain knowledge provided as an input parameter. Second, it creates a categorized attribute for each data column found in analyzed data table and inserts each attribute into a group of attributes based again on domain knowledge.
There is a simple analytical knowledge incorporporated into type of discretization of attributes:
- Columns with continuous (float) values are discretized into 10 equidistant intervals
- Columns with not more than 20 integer values (including date-part derived columns except for 'Year') are enumerated on principle one value is one category
- Columns with more than 20 integer values are discretized into 10 equifrequency intervals
- Columns with string values are enumerated up to 100 most frequent values
Analytical Tasks
This phase is executed by calling theems.tasks.createTasks()
from the main file and is implemented in the
<LM root>\Exec\Demo\EverMinerSimple\EMSTasks.lua file.
For now, only 4ft-Miner tasks are constructed for previously created groups of attributes and principle "each-to-each". So there is a task setting created for each group of attributes where it serves as succedent (on the right-hand side of association rule) and all other groups are on the left, as antecedents.
Parallel Processing
This phase is executed by calling theems.iterations.runAll()
from the main file and is implemented in the
<LM root>\Exec\Demo\EverMinerSimple\EMSIterations.lua
file.
Task processing algorithm description is in the Picture 2.
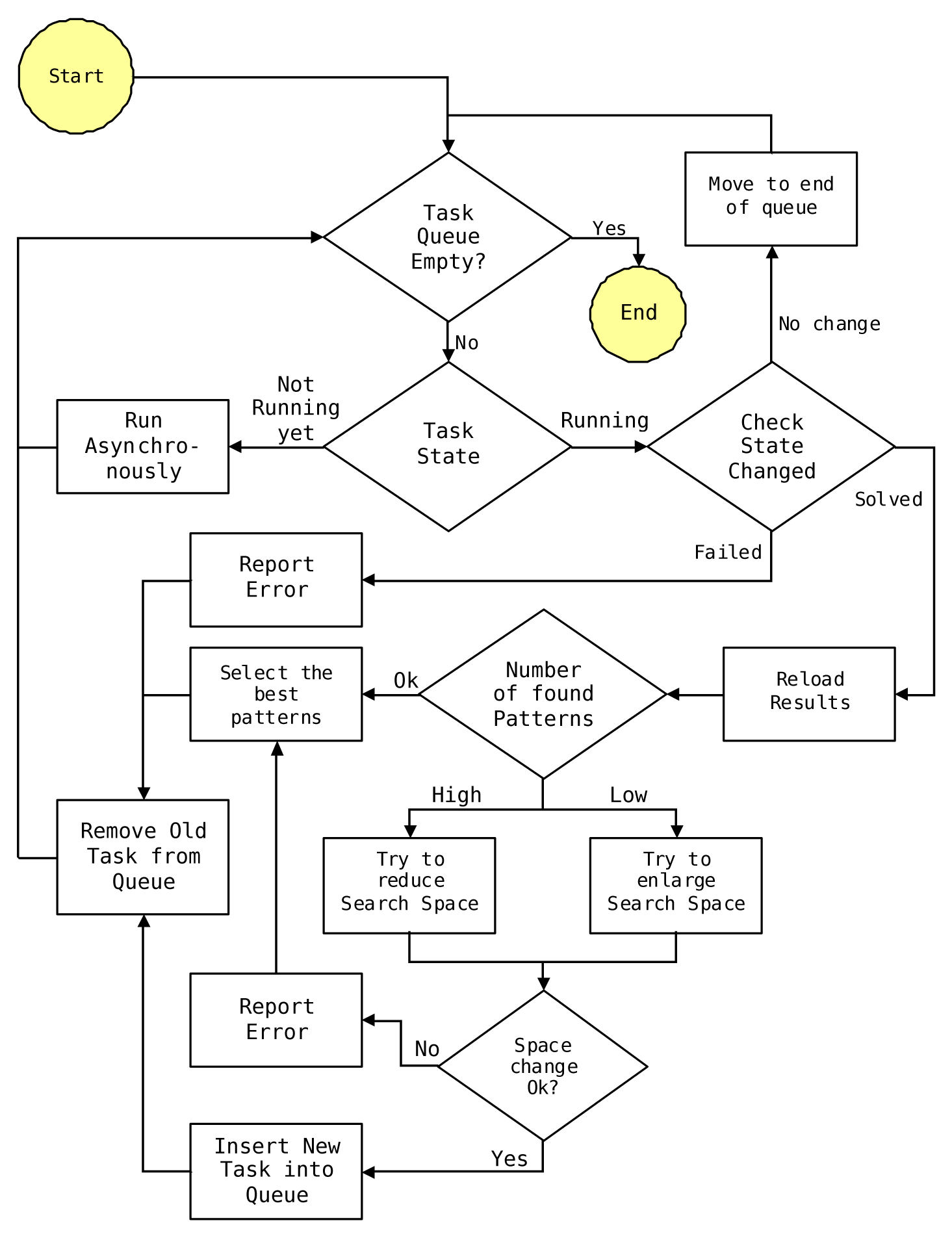
Pic. 2 -- Parallel Processing of tasks algorithm description
A loop is process till the queue is empty. It takes the first task in the
queue and checks its state. If the task is not computed yet, it starts an
asynchronous generation and verification of patterns by calling the ProcPooler
or GridPooler module, with regard to value of TargetPlatform input parameter.
If the task has already has been started, a query is made to metabase for the task state update. If its state has not changed yet, the task is moved to the end of the queue and the loop is repeated for another task.
If the task state has finished with some error, its state is changed to 'failed' and the task is removed for further processing.
If the task state has been solved successfully, found patterns are loaded and the execution forks based on the number of found patterns. If it is within the defined acceptable range, the "most interesting patterns" (in this simplified version just the "first two") are marked as "final results" to be included in the analytical report.
If the number of found patters is too low (respectively too high), the concerned task settings are changed to enlarge (respectively to reduce) the solution space searched. Changes to task settings are limited for now to a change of threshold values of 4ft-quantifiers of BASE and Founded Implication.
The important feature of task cloning is used. So no change is made to the
actual task setting, but its clone (an exact copy) is created first using the
Task.clone function. All the changes are
made to newly created copy and the previous task settings is preserved,
including the list of found patterns. So the whole history of task settings
changes is stored and available for a detail study of the path the automation
has taken.
If a new version of task settings is successfully created, it is inserted into task queue while the old task settings is removed. If it is not possible to further tweak task settings to get the acceptable number of hypothesis, the task is not further processed and this failure is mentioned in the final report.
Results Summary
The final report is created by calling theems.results.exportReport()
from the main file and is implemented in the
<LM root>\Exec\Demo\EverMinerSimple\EMSResults.lua
file.
There is an example of such a report included.